from sqlalchemy import create_engine
engine_file = create_engine("sqlite:///sqlite.db", echo=True)
engine_inmem = create_engine("sqlite:///:memory:", echo=True)
engine = engine_fileSQLAlchemy 1: Basics
Inleiding
In deze cursus leer je wat een ORM is en hoe je SQLAlchemy kan gebruiken om op een betere en handigere manier met een SQL database te werken vanuit je Python applicaties.
De cursus volgt grotendeels de uitstekende SQLAlchemy Unified Tutorial.
Terugblik
Tijdens de Flask lessen hebben we een SQLite database gebruikt m.b.v. het sqlite3 package uit de Python standard library.
Deze aanpak was prima voor een klein project maar wordt snel onhandig bij grotere applicaties en/of bij verdere ontwikkeling. - We werken rechtstreeks met SQL-strings. - We moeten queries aanpassen als de database verandert. - We moeten zelf fouten afhandelen. - Als we ooit willen overschakelen naar een andere database moeten we heel wat code volledig herzien.
Wat is een ORM
Een ORM (Object Relational Mapper) vertaalt (mapt) automatisch tussen objecten in een programmeeromgeving en tabellen in een relationele databank.
Met een ORM schrijf je dus minder ruwe SQL en werk je meer op het niveau van Python objecten. Je koppelt hiermee de business logic in de applicatie los van de onderliggende database. We spreken soms over “persistence ignorance”.
Code uit de Flask lessen als…
db.execute("INSERT INTO user (username, password) VALUES (?, ?)",
(username, generate_password_hash(password)))… wordt dan iets als…
user = User(name=username, password=generate_password_hash(password))
session.add(user)user zal dan een ‘echt’ User object zijn waarvan we attributen, zoals user.name, kunnen gebruiken!
ORMs zijn doorgaans ook database-agnostisch wat betekent dat je met geen of weinig aanpassingen in je code de onderliggende database kan veranderen!
ORMs zijn zeker niet uniek voor Python. Zo is er Hibernate voor Java of ODB voor C++.
SQLAlchemy
SQLAlchemy is dus een ORM (en eigenlijk de ORM voor Python), maar kan ook gebruikt worden louter als abstractielaag tussen applicatie en database.
SQLAlchemy bestaat uit twee grote onderdelen” - CORE - Engine: beheert de verbinding(en) met de database - SQL Expression Language: maakt het mogelijk SQL te bouwen met Python functies - Programmatisch definiëren van database schema - Imperatieve stijl - je specificeert precies hoe de database er uitziet en hoe data verwerkt wordt - import sqlalchemy - ORM - Object Relational Mapping - Mapt database rows and tables op Python objecten - Breidt de Core SQL Expression Language uit zodat SQL queries samengesteld en uitgevoerd kunnen worden op basis van deze objecten. - Declaratieve stijl - je beschrijft het model laat SQLAlchemy de rest doen - import sqlalchemy.orm

Tijdens deze cursus zullen we zowel SQLAlchemy Core als ORM bekijken.
SQLite
Net als bij Flask starten we in eerste instantie met SQLite als onderliggende database.
SQLite is ideaal om mee te starten omdat er geen server installatie nodig is en alles in één enkel bestand wordt beheerd. We kunnen dan later ook bekijken hoe je dankzij SQLAlchemy gemakkelijk naar een andere database kan overstappen, zoals PostgreSQL.
Bovendien mag SQLite tegenwoordig zeker als een volwaardige database systeem aanzien worden. SQLite ondersteunt ACID-transacties en volgt het SQL-standaarden. Heel wat applicaties gebruiken SQLite standaard als database, bvb. iMessage, Google Chrome of Dropbox.
Voorbereiding
SQLite CLI
De SQLite CLI is handig om handmatig te bekijken wat er precies in de database gebeurt. Als je deze notebook gebruikt via Google Colab of Binder kan je via de terminal sqlite als volgt installeren.
apt install sqlite3Voor andere platformen kan je terecht op https://sqlite.org/download.html.
Python Package
pip install sqlalchemy~=2.0
uv add sqlalchemy~=2.0
conda install sqlalchemy~=2.0De SQLAlchemy Engine
De engine is de centrale bron van alle verbindingen met een bepaalde database.
Er is typisch één global Engine object.
De engine definieert wat voor database gebruikt wordt (het dialect), bvb. postgresql of sqlite, als ook de details van die database (de connection string).
Om een Engine object de maken gebruik je de sqlalchemy.create_engine functie (een zogenaamde factory functie).
In het volgend voorbeeld maken we een engine voor een SQLite database in het locale bestand sqlite.db. Je ziet ook hoe je een engine zou maken voor een SQLite in-memory database. Dit laatste kan erg handig zijn bij testen. We werken nu eerst verder met een gewoon bestand zodat we de database zelf met de CLI kunnen inspecteren. Het echo=True argument zorgt er voor dat SQLAlchemy alle operaties (SQL) met de database logt. Zo kunnen we precies zien wat er gebeurt.
Er gebeurt eigenlijk nog niets. De engine gebruikt lazy initialization, wat in dit geval betekent dat er pas een verbinding met de database wordt gemaakt als die echt nodig is.
In de volgende stap werken we verder hetzelfde Engine object en gebruiken we de connect methode om een Connection object te krijgen. Van dat object gebruiken we de execute methode een rechtstreeks een standaard SQL commando uit te voeren. Door connect als context manager te gebruiken zorgen we er voor dat de verbinding automatisch terug vrij wordt gegeven (anders zouden we explicit the conn.close() methode moeten uitvoeren.). Op de text functie komen we later terug.
from sqlalchemy import text
with engine.connect() as conn:
result = conn.execute(text("SELECT 'hello world'"))
print(result.all())We zien dat: - De all() methode op het resultaat van de query een lijst met tuples teruggeeft. Elk tuple is één rij. - Als de context manager verlaten wordt is het standaard gedrag om een rollback (conn.rollback()) uit te voeren. Dit is een verstandig en veilig gedrag en dwingt het expliciet gebruik van conn.commit() indien er wijzigingen zijn die gecommit moeten worden.
Het Engine object bevat een connection pool. Hiermee houdt SQLAlchemy zelf automatisch verschillende database verbindingen bij die via engine.connect toegekend worden.
print(engine.pool.status())
with engine.connect() as conn:
print(engine.pool.status())
with engine.connect() as conn2:
print(engine.pool.status())
print(engine.pool.status())RAW SQL
Gaan we in principe niet gebruiken maar goed te weten dat dit kan.
CREATE, INSERT
with engine.connect() as conn:
conn.execute(text("CREATE TABLE some_table (x int, y int)"))
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 1, "y": 1}, {"x": 2, "y": 4}],
)
conn.commit()Door de text functie te gebruiken kunnen op een veilige en database-onafhankelijke manier variabelen (bound parameters) worden meegegeven.
De stijl van transactie heet commit-as-you-go omdat we expliciet the commit() methode moeten aanroepen.
Daar tegenover staat de begin-once stijl. Door een context manager met engine.begin() (i.p.v. engine.connect()) wordt er automatisch gecommit wanneer de context manager verlaten wordt.
with engine.begin() as conn:
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 6, "y": 8}, {"x": 9, "y": 10}],
)Optioneel: inspecteer de database met de sqlite3 CLI:
sqlite3 sqlite.db
.tables
.schema some_table
select * from some_table;SELECT
with engine.connect() as conn:
result = conn.execute(text("SELECT x, y from some_table"))
print(type(result))
for row in result:
print(f"row is a {type(row)}, row[0]={row[0]}, row.y={row.y}")Een Row object is vergelijkbaar met NamedTuple
from typing import NamedTuple
class FakeRow(NamedTuple):
x: int
y: int
fake_row = FakeRow(42, 9000)
print(f"fake_row[0]={fake_row[0]}, fake_row.y={fake_row.y}")SQL Parameters
Gebruik altijd bound parameters. Zo niet, dan loop je risico op SQL Injection en/of conversieproblemen. Door bound parameters te gebruiken zorgt SQLAlchemy automatisch voor de juiste escaping, quoting, en binding.
with engine.connect() as conn:
# Zonder bound parameters:
untrusted_variable = "1 OR 1=1"
result = conn.execute(text(f"SELECT y from some_table where x = {untrusted_variable}"))
print(list(result))
# Met bound parameters:
result = conn.execute(text("SELECT y from some_table where x = :x"), {"x": untrusted_variable})
print(list(result))Metadata
Wat is metadata?
Metadata is de interne representatie van de databasestructuur binnen SQLAlchemy, gebruik makend van Python objecten.
Basis objecten zijn MetaData, Table en Column.
+- equivalent van DDL in de database (Data Definition Language).
SQLAlchemy gebruikt deze metadata om SQL-statements te genereren, of je nu met Core of ORM werkt.
classDiagram
MetaData "1" *-- "*" Table
Table "1" *-- "*" ColumnMetadata met Core
from sqlalchemy import MetaData, Table, Column, Integer, String
metadata = MetaData()
user_table = Table(
"user_account",
metadata,
Column("id", Integer, primary_key=True),
Column("name", String(30)),
Column("fullname", String),
)
print(type(user_table.c))
print(repr(user_table.c.id))
print(user_table.primary_key)Een tweede table met een foreign key constaint.
ForeignKey krijgt een str met de table.column referentie, niet een Table of Column object zelf! ("user_account.id" ipv user_account.id)
from sqlalchemy import ForeignKey
address_table = Table(
"address",
metadata,
Column("id", Integer, primary_key=True),
Column("user_id", ForeignKey("user_account.id"), nullable=False),
Column("email_address", String, nullable=False),
)Met de voorgaande voorbeelden verkrijgen we een Python-representatie van de tables, nog zonder dat die fysiek bestaan in de database.
Met metadata.create_all() wordt voor alle informatie in de metadata aangepaste DDL uitgevoerd in de database.
metadata.create_all(engine)metadata.create_all is idempotent, wat wil zeggen dat je het verschillende keren kan uitvoeren zonder fouten te krijgen.
metadata.create_all(engine)Met metadata.drop_all worden de tables opnieuw verwijderd uit de database.Merk op dat dit in de juiste (omgekeerde) volgorde gebeurt.
metadata.drop_all(engine)Metadata met ORM
Mapped Class
Conversie (mapping) tussen data uit een database en objecten in een OO taal zoals Python.
Net zoals bij Core wordt een Metadata object gebruikt waarin de verschillende Table objecten worden bijgehouden. Dit (enkel) Metadata object wordt automatisch aangemaakt door sqlalchemy.orm.DeclarativeBase te subclassen in een eigen Base class. Elke Mapped Class wordt dan een subclass van Base en deelt daarmee dezelfde Metadata.
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
class Base(DeclarativeBase):
pass
print(Base.metadata)
class User(Base):
"""This Mapped Class represents a single user."""
__tablename__ = "user_account"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(30))
fullname: Mapped[str]Belangrijk: - Met Core gebruiken we de bestaande sqlalchemy.Table class en maken we direct objecten aan. - Elk object = 1 database table - Imperatief: we definiëren precies hoe de database structuur er uit moet zien - Met ORM maken we onze eigen nieuwe classes (mapped classes). - Elke class = 1 table - Elk object = 1 row. We hebben nog geen objecten gemaakt. - Declaratief: we definiëren wat voor objecten we willen en laten SQLAlchemy de overeenkomstige database structuur opstellen
Een DeclarativeBase subclass maakt automatisch een Table class aan (herinnering: ORM gebruikt Core!):
print(repr(User.__table__))class Address(Base):
__tablename__ = "address"
id: Mapped[int] = mapped_column(primary_key=True)
user_id: Mapped[int] = mapped_column(ForeignKey("user_account.id"))
email_address: Mapped[str]Net als bij ORM zal metadata.create_all() de database DDL genereren en uitvoeren. Via de Base class krijgen we toegang tot het metadata object.
Base.metadata.create_all(engine)Data verwerken met Core
In dit hoofdstuk bekijken we kort hoe SQLAlchemy Core gebruikt kan worden om met de database te werken. Ook al zijn we uiteindelijk van plan ORM te gebruiken, toch is het interessant ook te begrijpen hoe je rechtstreeks met de onderliggende Core kan werken. Heel wat concepten komen bovendien terug in ORM.
Waar we met Metadata en de Table objecten een abstractie kregen van de DDL, zo krijgen we hier een abstractie van de DML (Data Manipulation Language).
INSERT
from sqlalchemy import insert
"""
Ter herinnering, user_table is een OBJECT dat op een imperatieve manier
de 'user_table' tabel uit de database voorstelt:
user_table = Table(
"user_account",
metadata,
Column("id", Integer, primary_key=True),
Column("name", String(30)),
Column("fullname", String),
)
"""
statement = insert(user_table).values({"name": "wwhite", "fullname": "Walter White"})
print(type(statement))
print(statement)Met de sqlalchemy.insert functie en een Table object kunnen we op een programmatische manier een INSERT commando opstellen.
Net als na het aanmaken van een Table object is er enkel door het aanmaken van een Insert object nog geen interactie met de database. Er is immers nog geen gebruik gemaakt van de engine.
Uitvoeren gebeurt op dezelfde manier als het uitvoeren van zelfgeschreven SQL.
with engine.connect() as conn:
# Ter vergelijking, met 'raw SQL':
# result = conn.execute(
# text("INSERT INTO user_account (name, fullname) VALUES (:name, :fullname)"),
# {"name": "wwhite", "fullname": "Walter White"},
# )
statement = insert(user_table).values({"name": "wwhite", "fullname": "Walter White"})
result = conn.execute(statement)
conn.commit()
print(result)
print(result.inserted_primary_key)Met engine.begin() (i.p.v. engine.connect()) wordt automatisch gecommit bij het verlaten van de context manager.
statement = user_table.insert().values({"name": "jpinkman", "fullname": "Jesse Pinkman"})
with engine.begin() as conn:
conn.execute(statement)SELECT
Op gelijkaardige wijze kan met de sqlalchemy.select functie een SELECT statement samengesteld worden.
from sqlalchemy import select
statement = select(user_table)
print(type(statement))
print(statement)WHERE
De select functie geeft een Select object terug. Dit object heeft verschillende methodes waarmee de query verder verfijnd en aangepast kan worden, bijvoorbeeld .where(). Elke van deze functies geeft opnieuw een Select object terug. Op die manier kan de gewenste query samengesteld worden door verschillende functies aan elkaar te hangen (chaining).
from sqlalchemy import select
statement = select(user_table).where(user_table.c.name == "wwhite")
print(type(statement))
with engine.connect() as conn:
result = conn.execute(statement)
print(type(result))
for row in result:
print(type(row))
print(row)--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[1], line 3 1 from sqlalchemy import select ----> 3 statement = select(user_table).where(user_table.c.name == "wwhite") 4 print(type(statement)) 6 with engine.connect() as conn: NameError: name 'user_table' is not defined
Merk op dat het resultaat van de execute functie hetzelfde is als bij raw SQL, een CursorResult met Row objecten.
Als we specifieke kolommen van een tabel willen selecteren kan het .c attribuut van het Table object gebruikt worden. Dit kan gezien worden als een NamedTuple met alle Column objecten.
print(user_table.c)
statement = select(user_table.c.fullname)
with engine.connect() as conn:
result = conn.execute(statement)
for row in result:
print(row)AND - Impliciet door where() chaining - Impliciet door extra argument(en) in where() - Expliciet met and_()
from sqlalchemy import and_
statement1 = select(user_table).where(user_table.c.name == "wwhite").where(user_table.c.fullname == "Walter White")
print(statement1)
statement2 = select(user_table).where(user_table.c.name == "wwhite", user_table.c.fullname == "Walter White")
print(statement2)
statement3 = select(user_table).where(and_(user_table.c.name == "wwhite", user_table.c.fullname == "Walter White"))
print(statement3)
print(str(statement1) == str(statement2) == str(statement3))OR
- Met de
or_()methode, zelfde werkwijze alsand_(). - We laten direct ook het gebruik van twee methodes van het resultaat (
CursorResultobject) zien:
from sqlalchemy import or_
statement = select(user_table.c.name).where(or_(and_(user_table.c.name == "wwhite", user_table.c.fullname == "Walter White"), user_table.c.name == "jpinkman"))
print(statement)
with engine.connect() as conn:
result = conn.execute(statement)
print(result.all())
result = conn.execute(statement)
print(result.scalars().all())INSERT FROM SELECT
select_stmt = select(user_table.c.id, user_table.c.name + "@gmail.com")
insert_stmt = insert(address_table).from_select(["user_id", "email_address"], select_stmt)
with engine.begin() as conn:
conn.execute(insert_stmt)
select_stmt = select(user_table.c.id, user_table.c.name + "@amc.com")
insert_stmt = insert(address_table).from_select(["user_id", "email_address"], select_stmt)
conn.execute(insert_stmt)FROM en JOIN
FROMis impliciet voor alle tables gebruikt inselect()argumenten.- Probleem met het volgende?
statement = select(user_table.c.name, address_table.c.email_address)
with engine.connect() as conn:
result = conn.execute(statement)
print(result.all())Twee basis manieren om te joinen.
join_from(left_table, right_table)
-> FROM left_table JOIN right_table ON left_table.id = right_table.ref_id
statement = select(user_table.c.name, address_table.c.email_address).join_from(user_table, address_table)
with engine.connect() as conn:
result = conn.execute(statement)
print(result.all())join(right_table)
- left table is afgeleid
ONook afgeleid, maar kan je expliciet meegeven injoin()
print(select(user_table.c.name, address_table.c.email_address).join(address_table))
print(select(user_table.c.name, address_table.c.email_address).join(address_table, user_table.c.id == address_table.c.user_id))Outer en Full joins.
Herinnering:
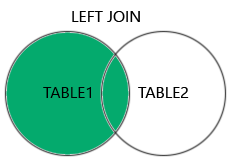
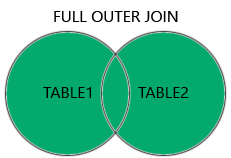
(bron: https://www.w3schools.com/sql/sql_join.asp)
print(
select(user_table.c.name, address_table.c.email_address).join(
address_table, isouter=True
)
)
print(
select(user_table.c.name, address_table.c.email_address).join(
address_table, full=True
)
)Functions
sqlalchemy.func voorziet verschillende functies die in combinatie met select() gebruikt kunnen worden.
Met func.count() krijg je een COUNT(*).
We gebruiken hier ook opnieuw scalars() op het resultaat om direct de waarde (i.p.v. een tuple) te krijgen. Met one() (i.p.v. all()) krijgen we enkel de eerste rij van het resultaat.
from sqlalchemy import func
statement = select(func.count()).select_from(user_table)
with engine.connect() as conn:
result = conn.execute(statement).scalars().one()
print(result)statement = select(func.upper(user_table.c.name))
with engine.connect() as conn:
result = conn.execute(statement).all()
print(result)Let op! - Ongedefinieerde functies worden letterlijk omgezet naar SQL
print(select(func.make_me_rich(user_table.c.name)))ORDER BY, GROUP BY, HAVING
Via order_by(), group_by() en having().
In het volgende voorbeeld gebruiken we ook label() een een kolom een specifiek label te geven (AS ...).
print(select(user_table).order_by(user_table.c.name))
print(
select(user_table.c.name, func.count(address_table.c.id).label("count"))
.join(address_table)
.group_by(user_table.c.name)
.having(func.count(address_table.c.id) > 1)
)UPDATE en DELETE
Werken op dezelfde manier als select(). Het resultaat heeft een rowcount attribuut met het aantal gewijzigde/verwijderde rijen.
from sqlalchemy import update
statement = (
update(user_table)
.where(user_table.c.name == "wwhite")
.values(fullname="Walter 'Heisenberg' White")
)
with engine.begin() as conn:
conn.execute(statement)from sqlalchemy import delete
statement = delete(user_table).where(user_table.c.name == "wwhite")
with engine.connect() as conn:
result = conn.execute(statement)
print(result.rowcount)Data verwerken met ORM
Ter herinnering: - Core: bestaande sqlalchemy.Table class. - Elk object = 1 table - ORM eigen nieuwe classes (subclasses van sqlalchemy.orm.Base) - Elke class = 1 table - Elk object = 1 row
Session
Met ORM gebruiken we een sqlalchemy.orm.Session i.p.v. een sqlalchemy.Connection - Session gebruikt Connection - Identieke execute() methode, kan ook op dezelfde manier en met Core Table objecten gebruikt worden
from sqlalchemy.orm import Session
with Session(engine) as session:
print(session.connection())
result = session.execute(select(user_table.c.name))
print(result.all())Relationschips
Uitdrukken van de relatie tussen (objecten van) mapped classes.
from sqlalchemy.orm import relationship
class Base(DeclarativeBase):
pass
class User(Base):
__tablename__ = "user_account"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(30))
fullname: Mapped[str]
addresses: Mapped[list["Address"]] = relationship(back_populates="user")
class Address(Base):
__tablename__ = "address"
id: Mapped[int] = mapped_column(primary_key=True)
user_id: Mapped[int] = mapped_column(ForeignKey("user_account.id"))
email_address: Mapped[str]
user: Mapped[User] = relationship(back_populates="addresses")user = User(name="wwhite", fullname="Walter White")
print(repr(user.name))
print(repr(user.addresses))Base.metadata.create_all(engine)Verandert niets aan de table DDL.
ORM specifiek:
Session … - Beheert alle interacties met de database - Tijdelijke opslagplaats voor ORM-objecten (Identity Map) - Houdt bij welke objecten geladen of gewijzigd zijn - Synchroniseert wijzigingen met de database (unit-of-work pattern)
SELECT
- Gebruikt dezelfde ‘SQL Expression Language’ als Core
sqlalchemy.select
Maar nu krijgen we ORM objecten terug! (met .first() krijgen we enkel de eerste rij)
with Session(engine) as session:
# Core:
result = session.execute(select(user_table)).first()
print(result)
# ORM:
result = session.execute(select(User)).first()
print(result)
print(result[0].name)Of nog …
with Session(engine) as session:
result = session.execute(select(User)).scalars().first()
print(result.id, result.name)
result = session.scalars(select(User)).first()
print(result.id, result.name)
result = session.get(User, 1)
print(result.id, result.name)
result = session.scalars(select(User).where(User.name == "wwhite")).one()
print(result.id, result.name)Lazy-loading: elementen uit relationships worden geladen (uit de database) op het moment dat ze nodig zijn.
with Session(engine) as session:
walter = session.get(User, 1)
print(walter.fullname)
print(walter.addresses)INSERT (add)
“Unit-of-Work” pattern - Mapped class objecten (=~ rows) worden toegevoegd (get, add) aan een Session - De Session houdt aanpassingen aan de objecten bij - Die worden wanneer nodig naar de database gestuurd (flush)
gus = User(name="gfring", fullname="Gus Fring")
print(gus)def user_repr(self) -> str:
return f"User(id={self.id!r}, name={self.name!r}, fullname={self.fullname!r})"
User.__repr__ = user_repr
print(gus)adr_1 = Address(email_address="gus.fring@hermanos.com")
gus.addresses.append(adr_1)
print(gus)
with Session(engine) as session:
session.add(gus)
session.flush()
print(gus)Zijn de nieuwe rows toegevoegd in database?
Wat me de id’s in de objecten?
saul = User(name="sgoodman", fullname="Saul Goodman", addresses=[Address(email_address="bettercallsaul@goodman.com")])
with Session(engine) as session:
session.add(saul)
session.commit()
print(saul)
print(gus)Let op! - Detached Instance - id bekend
with Session(engine) as session:
session.add(gus)
session.commit()
print(gus)gus = User(name="gfring", fullname="Gus Fring", addresses=[Address(email_address="gus.fring@hermanos.com")])
adr_2 = Address(email_address="gus.fring@amc.com", user=gus)
print(gus)
with Session(engine) as session:
session.add(gus)
session.commit()
print(gus)UPDATE
- = object aanpassen en committen
- aangepast object is “dirty”
Bonus: - filter_by ipv. where - scalar_one ipv scalars().one()
with Session(engine) as session:
gus = session.execute(select(User).filter_by(name="gfring")).scalar_one()
print(gus in session)
print(gus in session.dirty)
gus.fullname = "Gustavo Fring"
print(gus in session.dirty)
session.commit()DELETE
with Session(engine) as session:
bad_addr = session.execute(select(Address).filter_by(email_address="gus.fring@amc.com")).scalar_one()
session.delete(bad_addr)
session.commit()Extras
SQLAlchemy types en inspect
User.addresses is geen gewone list
user = User(name="wwhite", fullname="Walter White")
print(user.addresses)
print(type(user.addresses))
user.addresses.append("definitely not an Address object")from sqlalchemy import inspect
user = User(name="hschrader", fullname="Hank Schrader")
with Session(engine) as session:
print(inspect(user))
print(inspect(user).__dict__)
session.add(user)
print(inspect(user).__dict__)
session.flush()
print(f"XXXX {inspect(user).__dict__}")
session.commit()
print(f"XXXX {inspect(user).__dict__}")
print(user.id)
# lazy load
print(user.addresses)Dataclasses en SQLAlchemy
- Genereert automatisch
__init__,__repr__, … - Opslag van gestructureerde data
- Minder boilerplate-code zelf schrijven
from dataclasses import dataclass, field
@dataclass
class DC_User():
name: str
fullname: str
addresses: list[str] = field(default_factory=list)
user = DC_User(name="wwhite", fullname="Walter White")
print(user)Vergelijk gebruik in IDE (VSCode, PyCharm, …) met SQLAlchemy mapped class
from dataclasses import dataclass, field
from sqlalchemy import ForeignKey, String
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship
@dataclass
class DC_User:
name: str
fullname: str
addresses: list[str] = field(default_factory=list)
id: int = 0
class Base(DeclarativeBase):
pass
class SQLA_User(Base):
__tablename__ = "user_account"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(30))
fullname: Mapped[str]
addresses: Mapped[list["Address"]] = relationship(back_populates="user")
class Address(Base):
__tablename__ = "address"
id: Mapped[int] = mapped_column(primary_key=True)
user_id: Mapped[int] = mapped_column(ForeignKey("user_account.id"))
email_address: Mapped[str]
user: Mapped[SQLA_User] = relationship(back_populates="addresses")
# dc_user = DC_User(name="wwhite")
dc_user = DC_User(name="wwhite", fullname="Walter White")
print(dc_user)
sqla_user = SQLA_User(name="wwhite")
print(sqla_user)Oplossing: sqlalchemy.orm.MappedAsDataclass
class Base(MappedAsDataclass, DeclarativeBase):
passJOIN
with Session(engine) as session:
statement = (
select(Address.email_address)
.select_from(User)
.join(User.addresses)
.where(User.name == "wwhite")
)
for row in session.execute(statement).scalars().all():
print(row)Lazy Loading en Loader Strategies
with Session(engine) as session:
jesse = session.execute(select(User).filter_by(name="jpinkman")).scalar_one()
print(jesse.fullname)
print("Other things happen...")
print(f"{jesse.addresses[0].email_address} got lazily loaded")Kan leiden tot “N+1 Probleem”
with Session(engine) as session:
users = session.execute(select(User)).scalars() # 1 query
for user in users:
print([a.email_address for a in user.addresses]) # N queries!Oplossingen: - join (maar geen toegang tot addresses via User)
with Session(engine) as session:
users = session.execute(select(User, Address).join(User.addresses).order_by(User.id, Address.id))
for user, address in users.all():
print(f"{user.name} {address.email_address}")selectinload
from sqlalchemy.orm import selectinload
with Session(engine) as session:
users = session.execute(select(User).options(selectinload(User.addresses))).scalars()
for user in users:
print([a.email_address for a in user.addresses])Kan ook permanent in User class:
class User(Base):
__tablename__ = "user_account"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(30))
fullname: Mapped[str]
addresses: Mapped[list["Address"]] = relationship(back_populates="user", lazy="selectinloadˇ")Constraints en Indexes
from sqlalchemy import UniqueConstraint
engine = engine_inmem
class Base(DeclarativeBase):
pass
class User(Base):
__tablename__ = "user_account"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(30))
fullname: Mapped[str]
__table_args__ = (
UniqueConstraint("name", name="uq_user_name"),
)
Base.metadata.create_all(engine)u1 = User(name="wwhite", fullname="Walter White")
u2 = User(name="wwhite", fullname="Also Walter White")
with Session(engine) as session:
session.add(u1)
session.add(u2)
session.flush()from sqlalchemy import Index
Base.metadata.drop_all(engine)
class Base(DeclarativeBase):
pass
class User(Base):
__tablename__ = "user_account"
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column(String(30))
fullname: Mapped[str]
__table_args__ = (
UniqueConstraint("name", name="uq_user_name"),
Index("ix_user_name", "name")
)
Base.metadata.create_all(engine)PostgreSQL ipv sqlite
conda install psycopg2
createdb syntraengine = create_engine("postgresql://postgres@localhost/syntra", echo=True)
Base.metadata.create_all(engine)with Session(engine) as session:
session.execute(
insert(User),
[
{"name": "wwhite", "fullname": "Walter White"},
{"name": "jpinkman", "fullname": "Jesse Pinkman"},
{"name": "gfring", "fullname": "Gus Fring"},
{"name": "hschrade", "fullname": "Hank Schrader"},
{"name": "mehrmant", "fullname": "Mike Ehrmantraut"},
],
)
session.commit()with Session(engine) as session:
walter = session.get(User, 1)
print(walter.fullname)